Accelerating AI with NVIDIA B200: A Complete Quickstart Guide on HPC-AI.com
Unlocking the Power of NVIDIA B200: Quickstart Guide on HPC-AI.com
At HPC-AI.COM, we are excited to fully support the NVIDIA B200 architecture — empowering users with next-generation performance for AI and HPC workloads. In this blog, we will show you how to get started with B200 on our platform and maximize its power.

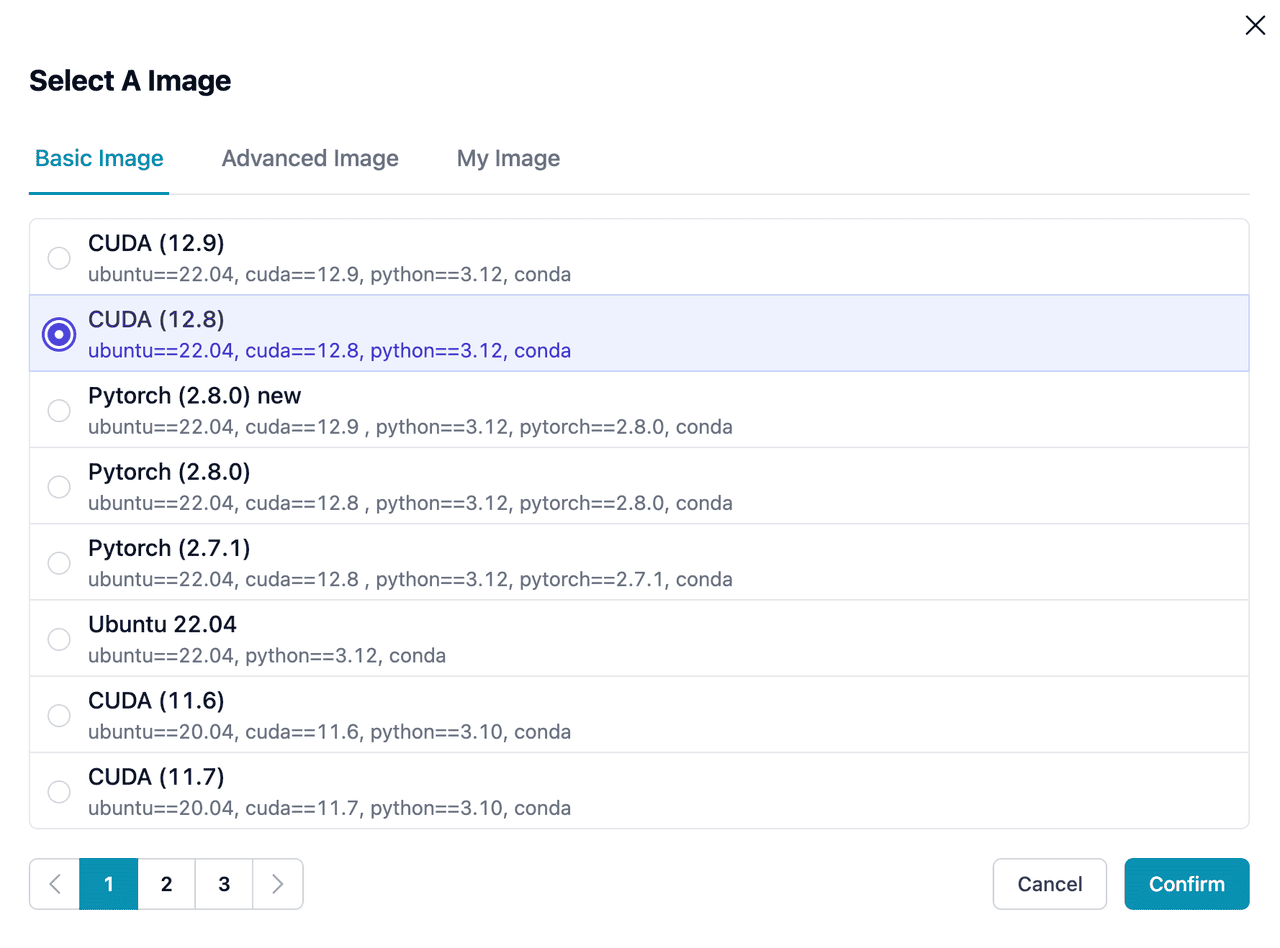
Getting Started: Launching a B200 Instance with CUDA 12.8+
Blackwell architecture requires CUDA version >= 12.8, do make sure the software (e.g. PyTorch, vLLM, SGLang) is compiled correctly. Here we select a base image with conda pre-installed, allowing you to easily manage dependencies and environments.
Set Up Your Conda Environment
To avoid conflicts between multiple applications running in the same container, we recommend creating a dedicated conda environment. This ensures a clean and efficient workspace:
# the following tutorial will be using vllm/sglang
# you may chooose either one here
$ conda create -n vllm python=3.10
$ conda activate vllm
You can choose to work with either vLLM or SGLang, depending on your use case.
Download the Model
Download on CPU instance with attached remote storage
Next, you will need to download your model to the server. We recommend to use remote storage to save GPU time and share data between different notebook (check https://www.hpc-ai.com/doc/docs/storage/ for details):
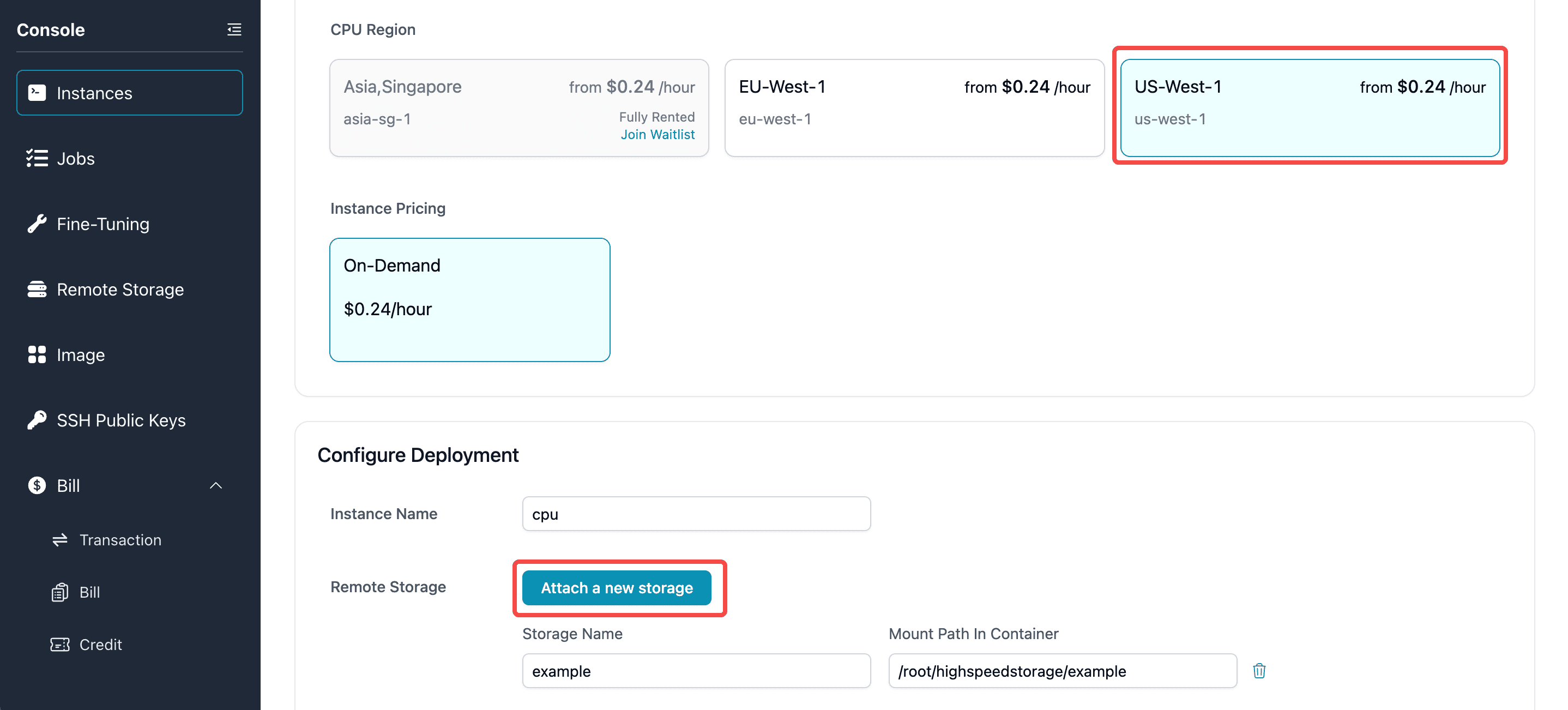
Firstly, create a CPU instance:

When launching a CPU instance, make sure the region is the same as the GPU instance you intend to use (for B200 users, please select US-West), then click on the button to attach a storage:
After launching the CPU instance, you can download the model weights with any tools you like.
$ pip install -U "huggingface_hub[cli]"
$ export YOUR_DOWNLOAD_PATH=/root/highspeedstorage/example # replace with local or attached storage
$ hf download Qwen/Qwen3-8B --local-dir $YOUR_DOWNLOAD_PATH/Qwen/Qwen3-8B
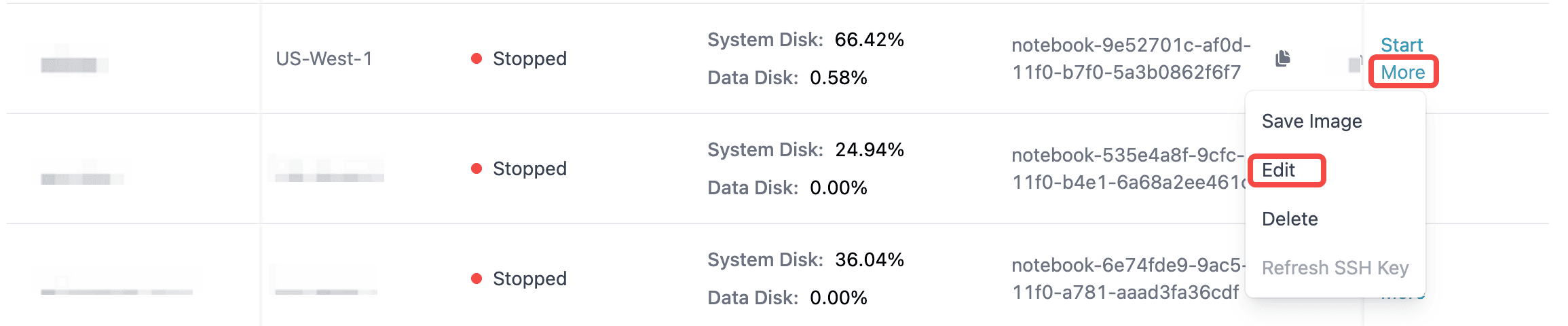
Attach the storage to GPU instance
To attach a storage to your GPU instance, navigate to your note book and find the Edit button.
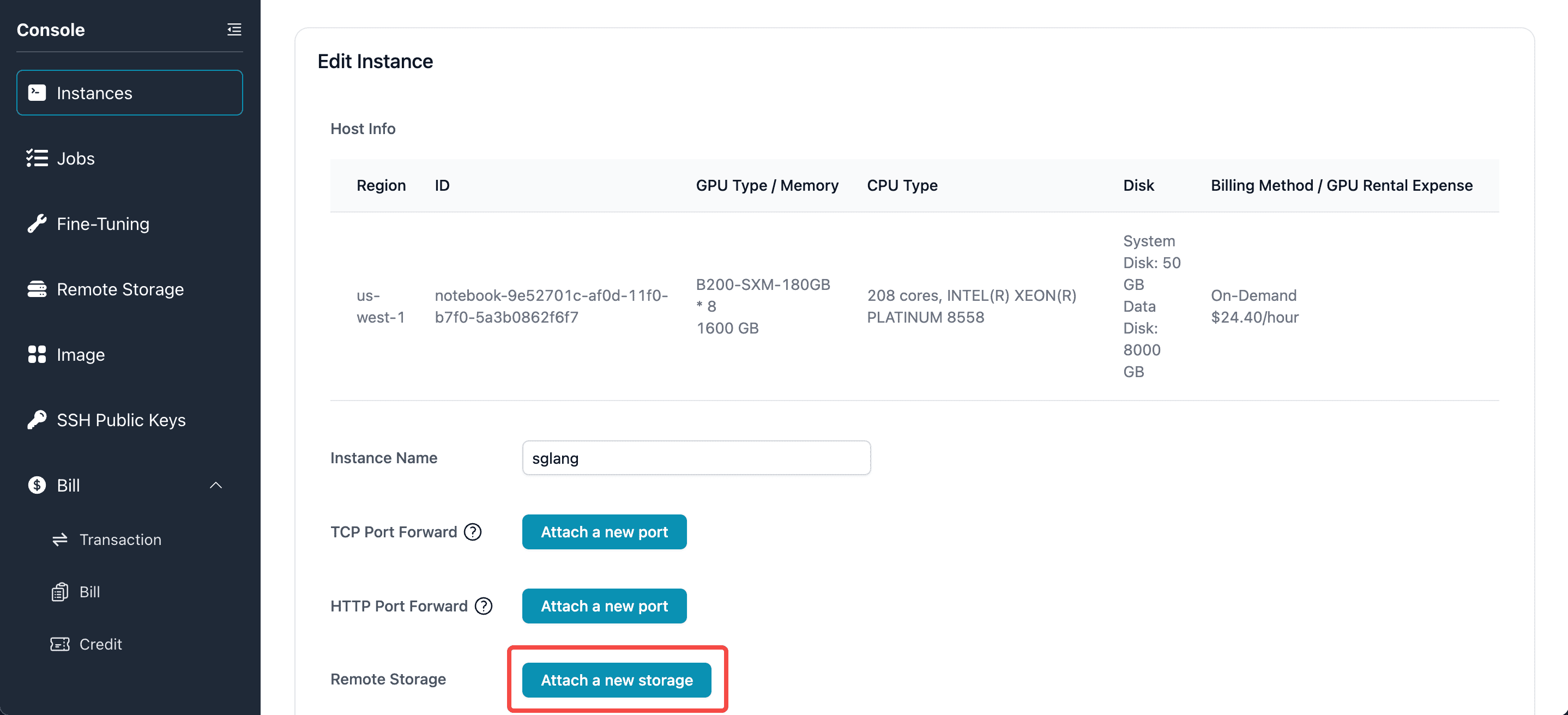
Follow the same procedure as above, you should see your storage appearing and ready to attach.
Serving Your Model: Framework-Specific Setup
Once the model is downloaded, the next step is to serve it using the appropriate framework. Below are instructions for vLLM and SGLang.
vLLM Framework
Environment Setup for vLLM
While your model downloads, you can begin installing the necessary dependencies for vLLM. Note that the installation process may vary depending on your package manager. For the most accurate instructions, always refer to the vLLM installation guide.
To install vLLM with CUDA 12.8 check the PyTorch version:
# Install vLLM with CUDA 12.8.
$ pip install vllm --extra-index-url https://download.pytorch.org/whl/cu128
# Check versions of important dependencies such as PyTorch
$ python -c "import torch; print(torch.__version__)"
# 2.8.0+cu128
Example request
# Launch server
$ cd $YOUR_DOWNLOAD_PATH && vllm serve Qwen/Qwen3-8B
# Send an HTTP request
$ curl -X 'POST' \
'http://0.0.0.0:8000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "Qwen/Qwen3-8B",
"prompt": "vLLM is a framework that ",
"max_tokens": 128
}'
SGLang Framework
Environment Setup for SGLang
Similarly, you can install the necessary dependencies for SGLang while the model is downloading. For the most up-to-date installation instructions, visit the official SGLang documentation.
To install SGLang and confirm the installation, you can check the versions of key dependencies:
# Install SGLang
$ pip install "sglang[all]>=0.5.3rc0"
# Check versions of important packages
$ pip freeze | grep -E "sglang|torch"
# 2.8.0+cu128
Example request
# Launch server
$ cd $YOUR_DOWNLOAD_PATH && python -m sglang.launch_server --model-path Qwen/Qwen3-8B
# Send an HTTP request
$ curl -X 'POST' \
'http://0.0.0.0:30000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "Qwen/Qwen3-8B",
"prompt": "SGLang is a framework that ",
"max_tokens": 128
}'
TensorRT-LLM with FP4 Precision
Beyond higher computing performance compared to the H200, B200 supports FP4 low-precision inference — delivering faster, more memory-efficient model execution and unlocking new possibilities for AI workloads.
Let’s take a quick example to let you experience the power of FP4.
Environment Setup for TensorRT-LLM
To optimize inference with FP4 precision, ensure your system meets the following requirements: Python 3.10 and CUDA Driver version 12.8 or higher. Then, proceed with the installation of the necessary libraries:
# make sure python==3.1.0, CUDA Driver >=12.8
pip3 install torch==2.7.1 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
pip3 install --upgrade pip setuptools && pip3 install tensorrt_llm
sudo apt-get -y install libopenmpi-dev
Download the FP4 Model Weights
Download the FP4-optimized model weights from Hugging Face:
hf download nvidia/Qwen3-8B-FP4 --local-dir $YOUR_DOWNLOAD_PATH/Qwen3-8B-FP4
Example request:
from tensorrt_llm import LLM, SamplingParams
def main():
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="$YOUR_DOWNLOAD_PATH/Qwen3-8B-FP4")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
# The entry point of the program needs to be protected for spawning processes.
if __name__ == '__main__':
main()
Performance Comparison on 1x B200 GPU
We benchmarked the Qwen3-8B models using both the FP4-optimized version and the standard version to compare inference times.
| Prompt | Generation Text | Generation Time (s) | Speed Up | |
|---|---|---|---|---|
| Qwen3-8B-FP4 | Write a short piece about Harry Potter | Harry Potter, the boy who lived, had always known he was different. From the moment he was left on the Dursleys' doorstep, he had been | 0.1291 | 1.26 X |
| Qwen3-8B | Write a short piece about Harry Potter | Harry Potter, the boy who lived, had always felt like an outsider in the wizarding world. Despite his extraordinary abilities, he often felt invisible, overshadowed | 0.1639 | 1.0 X |
Conclusion: Powering the Future of AI with B200
The NVIDIA B200 GPU delivers a transformative leap in performance, particularly for large-scale AI applications. Whether you are fine-tuning large language models or running inference-heavy workloads, the B200 is built for speed and scalability.
From faster model serving to optimized inference times, the B200 is the ideal choice for organizations seeking to accelerate their AI development pipeline. Start deploying B200 instances on HPC-AI.com today and experience the next frontier of AI performance.