Best LLM To Use For Coding in 2026
Large language models are rapidly transforming how developers write and review code. From generating boilerplate functions to debugging complex logic, modern LLMs now power many coding assistants and developer tools. However, not all models perform equally well when it comes to programming tasks. Some models specialize in reasoning and code generation, while others focus on general language understanding.
In this article, we compare some of the best LLMs for coding available today, examining their strengths, performance, and deployment considerations.

What Makes an LLM Good at Coding?
In order to find out which LLM is the best at coding, we first need to define what makes a good coding LLM. Coding tasks require slightly different capabilities than general conversational AI.
Strong coding models typically excel in several areas:
1. Code generation accuracy
The model should generate syntactically correct and logically sound code.
2. Understanding programming context
Good coding models can reason about existing codebases and maintain consistency with style and structure.
3. Multi-language support
Developers often work with multiple programming languages such as Python, JavaScript, Java, and C++.
4. Long context handling
Some tasks require reading large files or repositories, making long context windows important.
5. Fast inference speed & low latency
For production systems, teams must consider how easily the model can be deployed within their LLM infrastructure and scaled for AI inference workloads.
Top LLMs for Coding
Several models have emerged as strong performers for programming tasks.
MiniMax M2.5
MiniMax M2.5 is a high-performance large language model developed by MiniMax that demonstrates strong results across reasoning and coding benchmarks. It is designed to support complex tasks such as code generation, debugging, and software development assistance. The model is typically accessed through cloud APIs and is used in applications that require reliable performance and scalable AI inference.
Strengths:
-
strong reasoning and coding benchmark performance
-
good instruction-following and problem solving
-
scalable deployment through cloud APIs
Common use cases:
-
AI coding assistants
-
automated code generation
-
developer productivity tools
Kimi K2.5
Kimi K2.5 is a large language model developed by Moonshot AI and is known for its ability to process long contexts and complex prompts. The model performs well in reasoning-heavy tasks and can analyze large inputs such as lengthy code files or documentation. This makes it useful for development workflows that require understanding large codebases.
Strengths:
-
strong long-context processing capability
-
good reasoning across complex prompts
-
effective at analyzing large code inputs
Common use cases:
-
code review and repository analysis
-
development assistants for large projects
-
AI tools that process long documents or code files
DeepSeek Coder
DeepSeek Coder is one of the most popular open models designed for programming tasks. It was trained on large code datasets and optimized for developer workflows.
Strengths:
-
excellent code generation performance
-
strong reasoning for debugging tasks
-
good performance on programming benchmarks
Common use cases:
-
coding copilots
-
automated code documentation
-
debugging assistance
Many developer tools experimenting with open models use DeepSeek variants to run large language models locally or through hosted inference APIs.
Qwen (Coder Variants)
Qwen models developed by Alibaba also provide strong performance for coding tasks. Some variants are optimized for code understanding and software engineering workflows.
Strengths:
-
strong multilingual capabilities
-
good reasoning across complex prompts
-
large context windows for reading long code files
Qwen models are commonly used in enterprise environments where teams want to integrate LLMs into internal development workflows.
Claude (Anthropic)
Claude models have gained strong adoption for coding assistance due to their reasoning capabilities and ability to process large contexts.
Strengths:
-
excellent long-context support
-
strong code explanation ability
-
reliable reasoning for complex logic
Claude models are frequently used in tools that help developers analyze large repositories or review pull requests.
GPT Models
OpenAI’s GPT series remains widely used for coding assistants and developer tools.
Strengths:
-
strong reasoning and instruction-following
-
large ecosystem of developer tools
-
widely available through OpenAI compatible APIs
Many coding assistants rely on GPT models to power:
-
code generation
-
debugging suggestions
-
documentation writing
Coding Performance vs Inference Efficiency
While model capability is important, real-world deployments must also consider AI inference efficiency. Coding assistants often require low response latency, high concurrency, and stable output streaming. These requirements make GPU inference performance and infrastructure scalability critical factors.
Coding Performance
One commonly used benchmark for coding ability is HumanEval, which measures whether a model can generate correct solutions to programming problems.
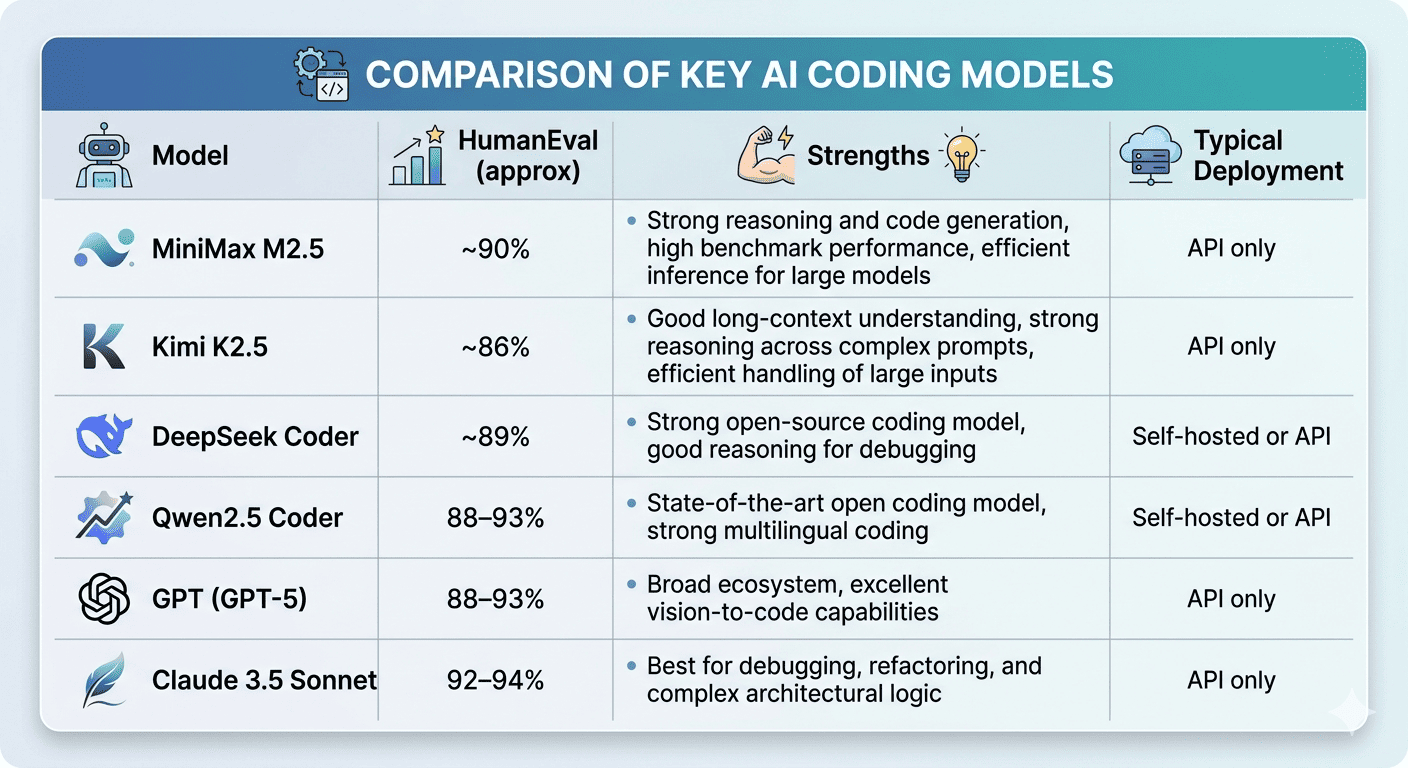 HumanEval data from https://llm-stats.com/benchmarks/humaneval, https://intuitionlabs.ai/articles/kimi-k2-open-weight-llm-analysis
HumanEval data from https://llm-stats.com/benchmarks/humaneval, https://intuitionlabs.ai/articles/kimi-k2-open-weight-llm-analysis
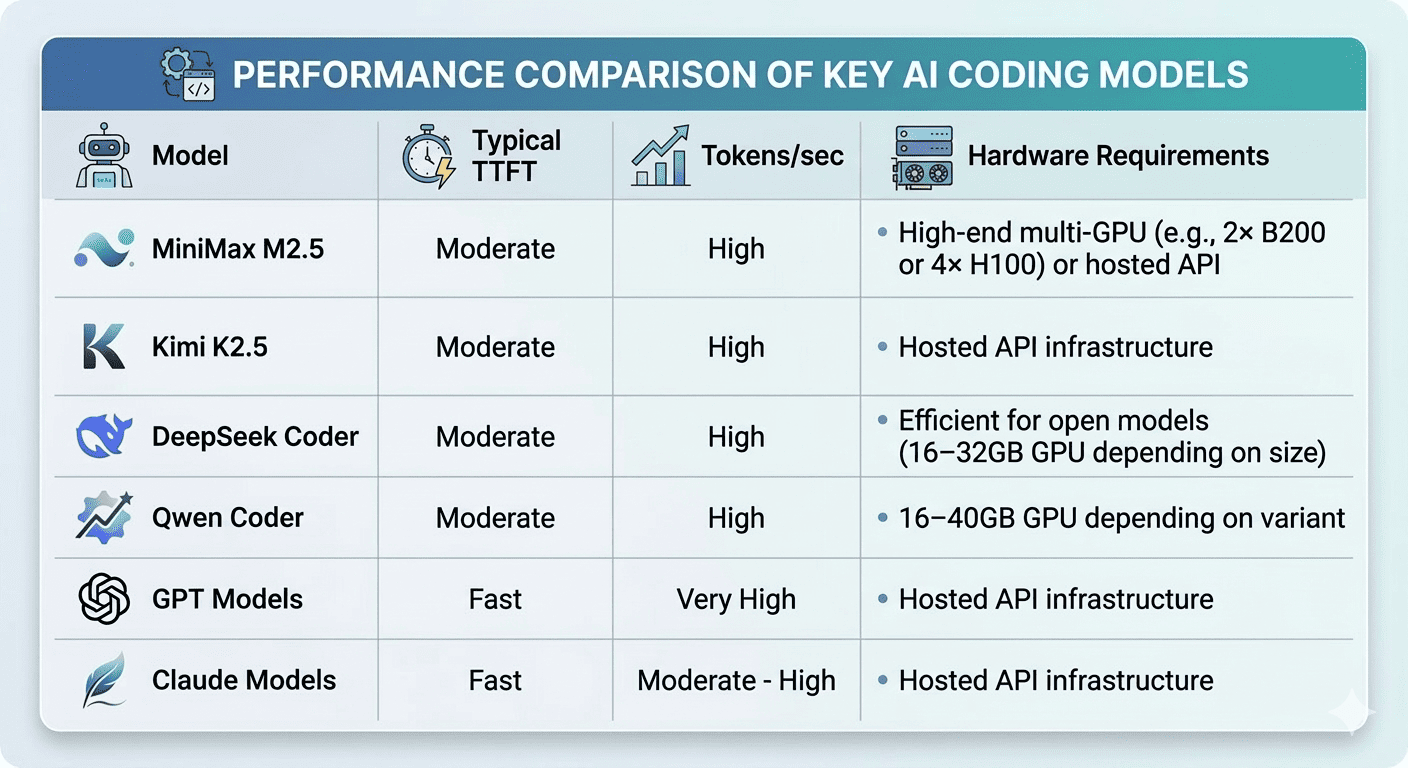
Inference Speed and Latency
Coding assistants require interactive responses, which makes inference latency an important factor when choosing a model.
Key metrics that affect the user experience include:
-
TTFT (Time to First Token) – how quickly the model begins generating a response
-
Tokens per second – the speed at which text is generated
-
GPU memory requirements – hardware resources needed to run the model efficiently
The following table provides a general comparison of inference characteristics across several popular coding models:
Choosing the Right Model
Different models each offer strong capabilities, but the right choice depends on factors such as coding performance, deployment flexibility, and AI inference requirements. As LLM infrastructure continues to evolve, developers will increasingly focus on not only model quality but also how easily they can deploy LLM systems and run large language models at scale. Choosing the right model, and the right infrastructure to support it, will be key to building reliable AI-powered development tools.
Choose MiniMax M2.5 if you want high benchmark performance and strong reasoning capabilities for complex coding tasks.
Choose Kimi K2.5 if your applications require strong long-context understanding and handling of large inputs.
Choose DeepSeek if you want code generation from open models.
Choose Qwen if you need multilingual capabilities and enterprise-friendly deployment.
Choose Claude if long context and reasoning over large codebases are important.
Choose GPT models if you want access to a mature ecosystem and widely supported APIs.
In practice, many developer teams experiment with multiple models before selecting the best option for their infrastructure and use case.