Taking On Thinking Machines Lab’s Tinker — HPC AI Fully Upgraded Fine-Tuning SDK
Embracing Post-Training and RL: Decoupling Algorithms from Underlying Compute Architecture
HPC-AI.COM is launching a serverless fine-tuning SDK compatible with the Tinker paradigm, designed for industrial-scale reinforcement learning (RL) with cost-effective token-based pricing.
We extend our gratitude to Thinking Machines Lab for their innovative Tinker. The HPC Fine-Tuning SDK, developed based on Tinker SDK[1], abstracts training into core primitives like forward, backward, and optimizer steps. This decouples algorithm design from complex distributed infrastructure, letting developers focus solely on defining data and loss functions, eliminating the hassle of cluster management or GPU reservations.
Embracing the post-training era, we eliminate the engineering gap between algorithm research and model deployment. By handling heterogeneous scheduling, fault tolerance, and parallel strategy optimization behind the scenes, we provide a seamless "Training as a Service" experience—where you code locally and compute in the cloud, with every penny spent on meaningful gradient generation.
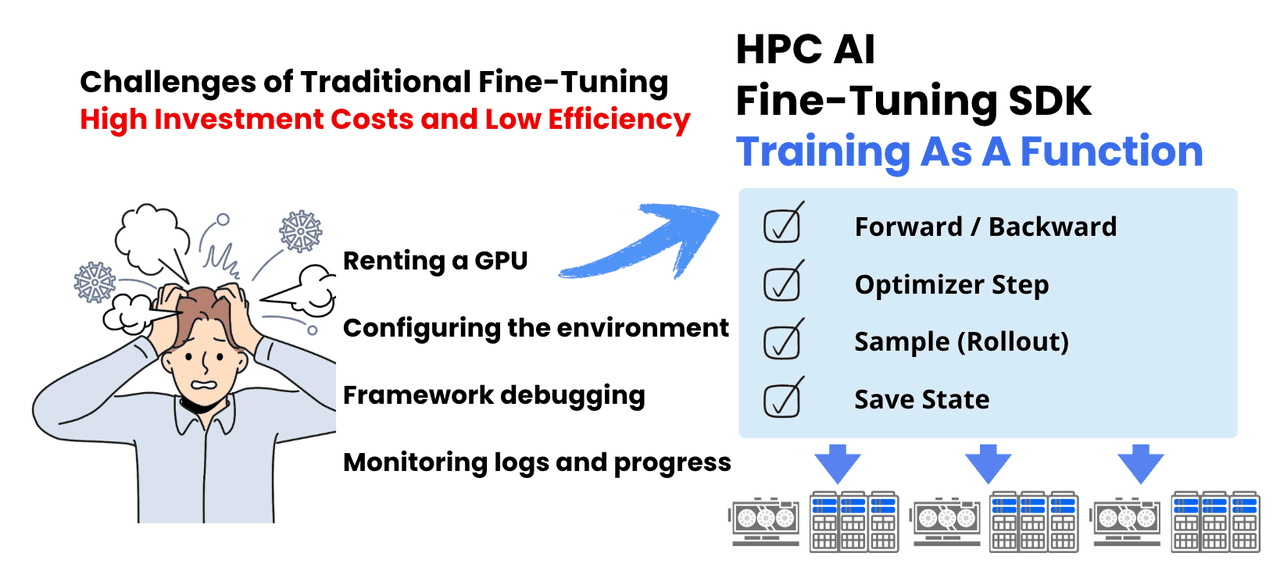
Disruptive Human Efficiency: 1 Algorithm Engineer Replaces a Full Infra Team
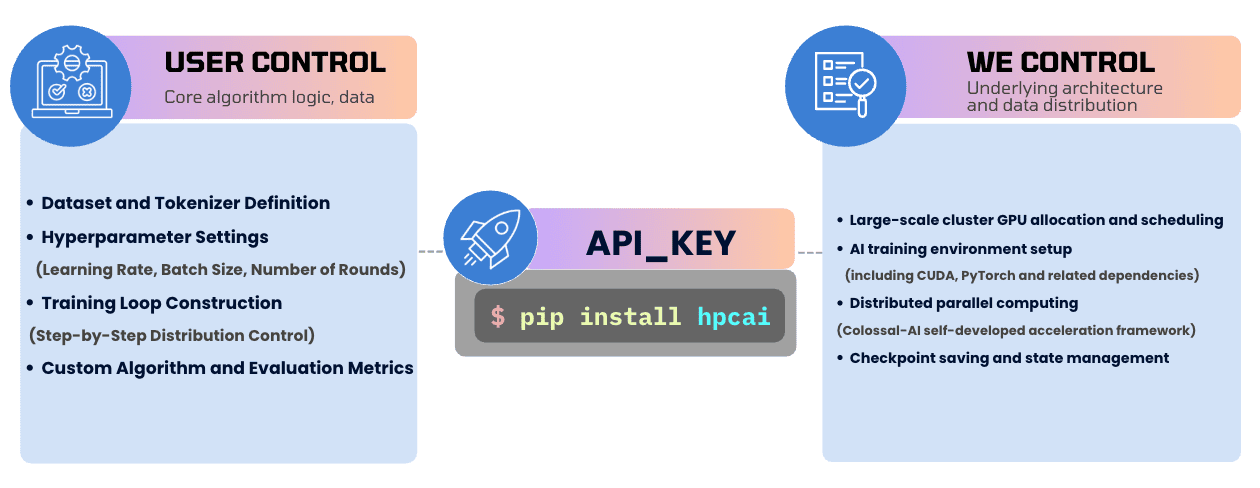
The core philosophy of HPC-AI.COM’s Fine-Tuning SDK is simple: you define the algorithm logic; we handle the infrastructure.
Traditionally, developers spent countless hours renting GPU clusters, managing environments, tweaking training frameworks, and maintaining clusters. HPC-AI.COM changes this by breaking large model training into a set of standard function primitives—covering the full pipeline from supervised fine-tuning (SFT) to RL:
-
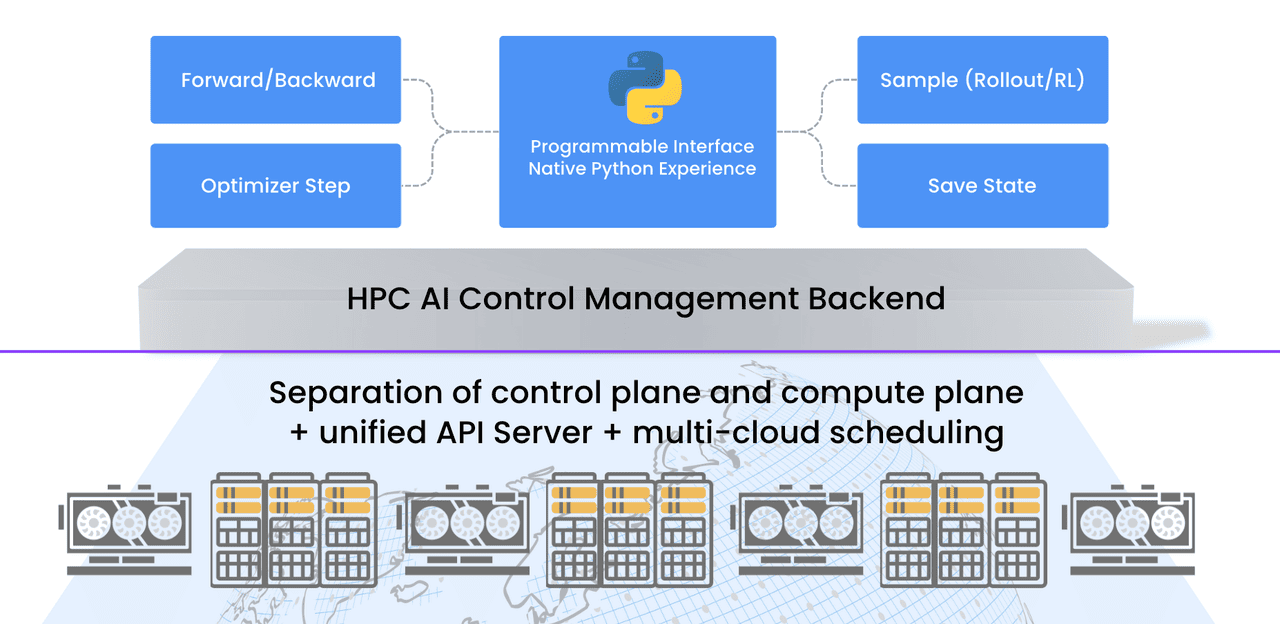
Forward & Backward: Handles forward propagation and gradient calculation
-
Optimizer Step: Executes weight update strategies
-
Sample (Rollout): Enables inference, generation, and evaluation—supporting not just SFT, but complex RL (RLHF/RLAIF) workflows like PPO, GRPO, and DPO
-
Save State: Manages model checkpoints and state preservation
This means you can use familiar local tools like Jupyter Notebook or your favorite IDE, combining these primitives like building blocks with standard Python syntax to take full control of training logic.
The impact? Game-changing human efficiency. What once required a large team of DevOps engineers, infra specialists, platform engineers, and algorithm engineers can now be done by a single algorithm engineer.
No more being bogged down by infrastructure, no more juggling multiple roles, no more passively tweaking parameters in black boxes. You’re now the architect of large-scale training workflows—whether it’s SFT or complex RL pipelines—all built by combining these atomic functions.
Why the Experience Feels So Seamless
To deliver this frictionless experience, we’ve built a complete backend system on our existing GPU cloud service architecture. Key design choices include:
-
Separation of control and compute planes: A unified API Server manages multiple cross-regional GPU clusters, enabling multi-cloud deployment.
-
Asynchronous Future-based APIs: All training operations support non-blocking calls—you can keep coding while GPU computations run in the background.
-
Intelligent persistent queue: During resource peaks, tasks automatically enter a persistent queue. Once resources free up, they launch in milliseconds—with zero charges while waiting. You only pay for tokens used in prefill, sampling, and training—no idle resource costs.
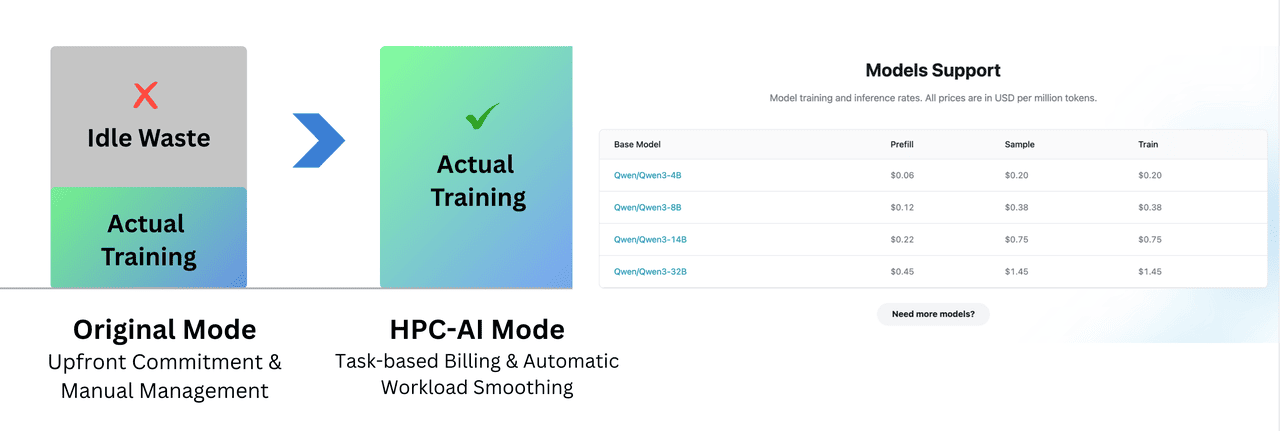
The Compute "Retail Revolution" for Fine-Tuning: From "Cluster Leasing" to "Token-Based Pricing"
If usability is the entry ticket for post-training platforms, cost structure is the moat that determines long-term success.
In traditional "cluster/hourly leasing" models, you pay for the "process"—whether you’re loading data, debugging code, or just refining your loss function. Over half your budget gets wasted on unproductive "dead time."
HPC-AI.COM transforms this with Serverless architecture for fine-tuning, pioneering a "token-based pricing" model that splits compute services into the finest granularity:
-
Pay for value: Like using inference APIs, you only pay for valid compute tokens from prefill (input), sampling (inference output), and training.
-
Free non-productive steps: Local code debugging, environment setup, data preprocessing, model checkpoint saving—all free, no more rushing against the clock.
-
Unbeatable cost-effectiveness: RL typically requires maintaining high-throughput inference clusters (vLLM) and training clusters, driving up costs. But on HPC-AI.COM, running a full RL pipeline (~300 steps) including rollout sampling, reward scoring, and PPO updates via our official math_rl cookbook costs just $1.23. Individual developers can now reproduce RLHF/RLAIF experiments at a fraction of the traditional cost.
Three Scenarios Where Technology Meets Reality: SFT and RL, Ready Out of the Box
This new model redefines workflows across sectors:
1. Research: Say Goodbye to Resource Anxiety
In academia, time and compute are scarce. Researchers grapple with tedious cluster maintenance (Slurm/Docker configurations) and high experiment reproduction costs. Our Fine-Tuning SDK supports "white-box" research, fully compatible with Tinker APIs. Customize evaluation logic, precisely control post-training and RL pipelines via primitives like Forward/Backward and Sample—no need to worry about distributed implementations. Experiment reproduction costs plummet.
2. Startups & Independent Developers: Rapid MVP Validation
For startups, speed is survival. With our Serverless design, no more waiting for resource scheduling. Combined with ultra-low token costs, you can go from pip install to running an SFT or RL fine-tuning experiment with 1,000 samples in minutes. This extreme marginal cost lets you iterate on reward models quickly within budget—true "low-cost trial and error."
3. Industrial Deployment: Overcoming Complex Architectures
In vertical industries like finance and healthcare, existing fine-tuning APIs often can’t handle complex heterogeneous architectures or RLHF/RLAIF needs. Our Fine-Tuning SDK lets engineers freely define loss logic and RL reward functions via train_step. Full control over model weights and training details enables end-to-end customization.
Ultra-Simple Getting Started: 3 Steps to Train Your Model
No complex cluster configurations, no lengthy Docker builds. Training a large model with HPC-AI.COM’s Fine-Tuning SDK is as simple as writing a Python script:
1. Install & Import:
pip install hpcai
2. Initialize Client:
We currently support the Qwen3 series (0.6B - 32B), with more models coming soon
import hpcai
# Initialize LoRA training client—no complex distributed parameters needed
training_client = service_client.create_lora_training_client(
base_model="Qwen/Qwen3-4B",
rank=32
)
3. Define Training Loop & Run:
Take full control of the training loop, just like writing PyTorch locally
# Training Loop: Fully Controllable
for step in range(target_steps):
# Forward and Backward Propagation
fwd_bwd = training_client.forward_backward(batch, "cross_entropy")
# Optimizer Stepping
optim = training_client.optim_step(adam_params)
# Real-time Loss Monitoring
loss = fwd_bwd.result().metrics.get("loss:mean")
Today, our Fine-Tuning SDK covers the Qwen3 model series (4B, 8B, 14B, 32B) and supports both SFT and RL. We’ll continue expanding model support and use cases—feel free to submit feature requests to drive updates.
We’ve also prepared the out-of-the-box HPC-AI Cookbook, with complete code implementations for complex RL scenarios: DeepSeek R1’s GRPO algorithm[2], verifier-based math reasoning, custom reward functions, and more. No need to build PPO/GRPO pipelines from scratch—copy the "recipes" from the Cookbook, run a lightweight local train.py script, and drive complex distributed RL training workflows in the cloud. Reproduce SOTA models with advanced logical reasoning capabilities on HPC-AI.COM.
Experience Now
Post-training is evolving from an academic side project to a core engineering focus. The ultimate AI infrastructure should be "zero cognitive load"—you describe your data and algorithms, and we handle the rest (GPU rental, environment setup, parallel strategies, operations, fault recovery, and all the engineering work involved in RL). When GPU idle costs approach zero, environment setup time approaches zero, and long-sequence RLHF is priced by token, application innovation efficiency will directly approach the limits of compute power.
HPC-AI.COM’s Fine-Tuning SDK is now fully open:
-
No whitelist, no reservations required
-
The first 100 users to register via our exclusive link get $10 in usage credits: https://www.hpc-ai.com/account/signup?invitation\_code=HPCAI
-
Existing users can log in to the console and access the Fine-tuning SDK to claim $5 credit
Leave resource elasticity to the platform, keep algorithmic freedom for yourself, and ensure every penny drives gradient generation!
-
Start Fine-Tuning SDK Now: https://www.hpc-ai.com/fine-tuning
-
View Documentation: https://www.hpc-ai.com/doc/docs/finetune-sdk/
References
[1] Tinker SDK: https://github.com/thinking-machines-lab/tinker
[2] DeepSeek-R1: https://arxiv.org/pdf/2501.12948